
SaaS, agent-based, and mobile applications designed and built for you
Bring your ideas to life with our technological expertise. We develop solutions that propel your performance and innovation.
You accelerate. We build. You perform.
Explore our solutions
Our clients
Our expertise at the service of your ambitions
Do you have ideas? A project to bring to life? An application to upgrade or modernize?
In close collaboration with your teams, we design tailor-made, robust, and scalable solutions, perfectly aligned with your business objectives. We turn technology into a true driver of growth and a strategic asset for your organization.
Move from idea to action
A 360° solution to transform your ambitions into success
01
Audit, consulting and strategy
02
Web and mobile development & design
03
Cloud infrastructure implementation and migration
04
AI agent design and implementation
05
Proactive maintenance and continuous monitoring
'%20fill='%232E6971'/%3e%3ccircle%20cx='316.083'%20cy='20.083'%20r='1.38871'%20transform='rotate(-180%20316.083%2020.083)'%20fill='%235FE2DC'/%3e%3ccircle%20cx='499.43'%20cy='50.4301'%20r='2.43024'%20transform='rotate(-180%20499.43%2050.4301)'%20fill='%232E6971'/%3e%3ccircle%20cx='499.083'%20cy='50.083'%20r='1.38871'%20transform='rotate(-180%20499.083%2050.083)'%20fill='%235FE2DC'/%3e%3ccircle%20cx='414.43'%20cy='97.4301'%20r='2.43024'%20transform='rotate(-180%20414.43%2097.4301)'%20fill='%232E6971'/%3e%3ccircle%20cx='414.083'%20cy='97.083'%20r='1.38871'%20transform='rotate(-180%20414.083%2097.083)'%20fill='%235FE2DC'/%3e%3ccircle%20cx='71.4301'%20cy='2.43012'%20r='2.43024'%20transform='rotate(-180%2071.4301%202.43012)'%20fill='%232E6971'/%3e%3ccircle%20cx='71.0832'%20cy='2.08297'%20r='1.38871'%20transform='rotate(-180%2071.0832%202.08297)'%20fill='%235FE2DC'/%3e%3ccircle%20cx='66.4301'%20cy='59.4301'%20r='2.43024'%20transform='rotate(-180%2066.4301%2059.4301)'%20fill='%232E6971'/%3e%3ccircle%20cx='66.0832'%20cy='59.083'%20r='1.38871'%20transform='rotate(-180%2066.0832%2059.083)'%20fill='%235FE2DC'/%3e%3ccircle%20cx='1.04153'%20cy='1.04153'%20r='1.04153'%20transform='matrix(-0.5%200.866025%200.866025%200.5%20141.042%2023)'%20fill='%231B313A'/%3e%3ccircle%20cx='0.59516'%20cy='0.59516'%20r='0.59516'%20transform='matrix(-0.5%200.866025%200.866025%200.5%20141.259%2023.813)'%20fill='%235FE2DC'/%3e%3ccircle%20cx='1.04153'%20cy='1.04153'%20r='1.04153'%20transform='matrix(-0.5%200.866025%200.866025%200.5%20247.042%2042)'%20fill='%231B313A'/%3e%3ccircle%20cx='0.59516'%20cy='0.59516'%20r='0.59516'%20transform='matrix(-0.5%200.866025%200.866025%200.5%20247.259%2042.813)'%20fill='%235FE2DC'/%3e%3ccircle%20cx='1.04153'%20cy='1.04153'%20r='1.04153'%20transform='matrix(-0.5%200.866025%200.866025%200.5%20226.042%2096)'%20fill='%231B313A'/%3e%3ccircle%20cx='0.59516'%20cy='0.59516'%20r='0.59516'%20transform='matrix(-0.5%200.866025%200.866025%200.5%20226.259%2096.813)'%20fill='%235FE2DC'/%3e%3c/svg%3e)
Our approach to unlock the potential of your projects
Our priority: delivering value through the synergy of people and technology.
Projects and case studies
From San Francisco to Paris to Quebec City, startups and multinationals have trusted us to develop their SaaS products. Why not you?
Artificial Intelligence
XTrace
A solid SaaS foundation for an innovative AI SDK
A flexible, secure and scalable SaaS architecture, allowing users to manage their encrypted data and subscriptions independently.
Environment
WaterShed Monitoring
From data optimization to environmental impact
Aggregate and optimize millions of data for real impact and sustainable development.
Environment
Quebec Forest Industry Council
From manual entry to automation
Improve the operational efficency of Quebec wood stakeholders through digital innovation
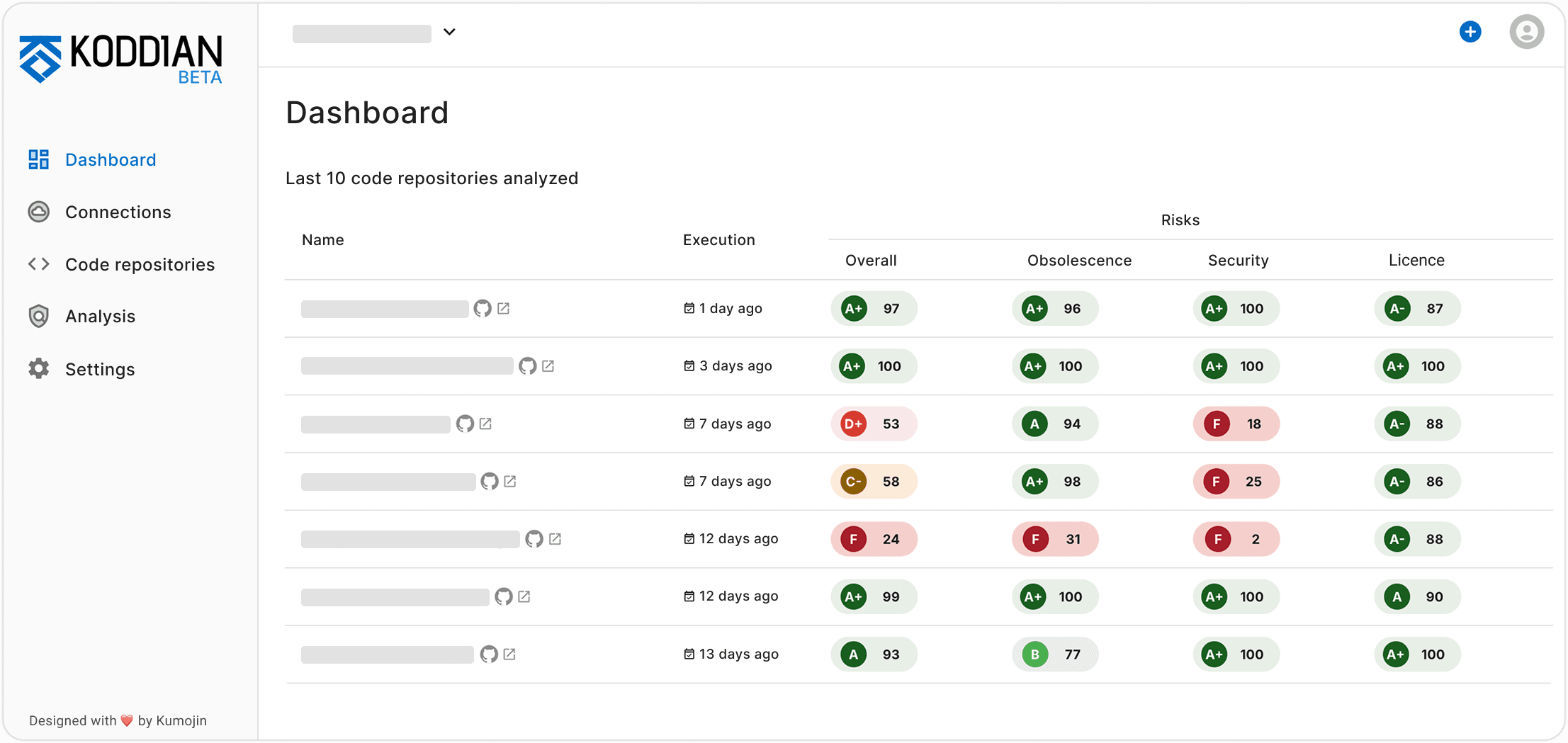
KODDIAN: Manage your technical debt, prioritize your developments
Are you prepared to handle open-source vulnerabilities?
-
Keep control over the health of your applications
-
Generate your reports and your SBOM in one click
-
Don't miss anything and watch your licenses
-
Identify your vulnerabilities and dependencies before they become a risk
-
Stay up to date, fight obsolescence
-
Let AI guide you to the priorities that matter

ARE YOU WILLING TO TAKE THE RISK?
We'd rather keep an eye on it!
Empower your projects with Koddian
People first
Develop your career and progress within a close-knit team that combines personal and professional growth. Join our community and take part in innovative and varied projects where your human and technical skills will be valued.
Are you passionate about coding? Contact us now!
Ready for your next challenge?